必须掌握的Linux操作
解压 *.tar.gz 安装包
1 | #tar -zxvf {path} -C {out path} |
ssh操作(可能已经配置好了,那直接看最后两步就行)
安装ssh
1 | #yum install -y openssl openssh-server |
生成密钥
1 | #ssh -keygen -t rsa |
将私钥写入公钥
1 | #cd /root/.ssh/ |
ssh复制文件或目录
1 | 单个文件 |
多台服务器免密登陆配置
1 | 每台服务器都完成上面前两个操作后 |
登陆/退出其他服务器命令
1 | #ssh 服务器ip |
关闭防火墙操作
1 | 停止防火墙 |
查看ip
1 | #ip a |
vim操作
编辑文档或配置文件操作
1 | #vi path |
查找操作(在配置hive时会用到)
1 | 在用vi打开文件后,输入/**str 回车即可查找堪忧str的位置 |
退出
1 | shift+zz或者:wq 保存退出 |
系统环境变量
编辑环境变量
1 | vi ~/.bashrc |
添加环境变量(举个例子)
1 | export PATH=$PATH:/usr/local/jdk1.8.0_221 |
应用环境变量
1 | source ~/.bashrc |
修改文件或目录的所有者
1 | # chown -R 用户名 path |
安装zookeeper
解压zookeeper至指定位置
进入zookeeper目录/conf
1 | cd /usr/local/zookeeper/conf |
编辑配置文件
1 | vi zoo.cfg |
创建data和logs目录
1 | cd /usr/local/zookeeper |
加入机器的id标识
1 | cd /usr/local/zookeeper/data |
将zookeeper文件目录分发至其他服务器
1 | scp -r /usr/local/zookeeper 服务器id:/usr/local/ |
配置环境变量,并分发至各个服务器
在每个服务器启动zookeeper
1 | zkServer.sh start |
zookeeper的启动必须是每台服务器都启动,zookeeper会自动选择一台作为leader,其他的作为follower
安装配置hadoop
解压hadoop
修改配置文件
在hadoop-env.sh和mapred-env.sh还有yarn-env.sh中
写上你的jdk路径(有可能这条属性被注释掉了,记得解开,把前面的#去掉就可以了)
修改hdfs配置文件
配置core-site.xml
1 |
|
配置hdfs-site.xml
1 |
|
配置slave
DataNode、NodeManager决定于:slaves文件。(默认localhost,删掉即可)
谁跑dataNode,slaves文件写谁。当namenode跑的时候,会通过配置文件开始扫描slaves文件,slaves文件有谁,谁启动dataNode.当启动yarn时,会通过扫描配置文件开始扫描slaves文件,slaves文件有谁,谁启动NodeManager1
2vi salves
写入想作为namenode的节点,一般是前两台服务器,即master 和 slave1
修改yarn配置文件
配置mapred-site.xml
1 | <configuration> |
配置yarn-site.xml
1 |
|
将hadoop目录分发值其他服务器
修改环境变量
启动journalnode服务
1 | 启动Journalnode是为了创建namenode元数据存放目录 |
格式化主Namenode
在主namenode节点执行1
hdfs namenode –format
查看一下是否已经生成了tmp目录
启动主Namenode
1 | hadoop-daemon.sh start namenode |
同步主Namenode(hadoop1)的信息到备namenode(hadoop2)上面
1 | 在备用节点上运行 |
只在主NameNode上格式化zkfc,创建znode节点
1 | hdfs zkfc –formatZK |
停掉主namenode和所有的journalnode进程
1 | [hadoop@hadoop1 ~]$hadoop-daemon.sh stop namenode |
启动hdfs并用jsp检查进程
start-dfs.sh
有可能没有datanode
datanode的clusterID 和 namenode的clusterID 不匹配
查看namenode节点上的cluserID
在current目录下有一个VERSION文件,用name下的那个VERSION中的 clusterID 覆盖 data下的VERSION中的clusterID
启动yarn集群
1 | 在主节点上运行 |
在备节点上手动启动resourceMabager
1 | yarn-daemon.sh start resourcemanager |
web页面
hdfs页面
在网页中输入 ip:50070
yarn页面
在网页中输入 ip:8088
完成所有配置后,hadoop的启动停止可以使用
1 | start-all.sh |
Hive+Mysql配置
安装mysql
1 | 进入下载目录 |
重启mysql
1 | #service mysqld restart |
初始化获取随机密码
1 | #grep "password" /var/log/mysqld.log |

登陆mysql
1 | #mysql -u root -p |
更改密码
1 | mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '12Zhang.'; |
添加root用户的远程登录权限
默认只允许root帐户在本地登录,如果要在其它机器上连接mysql,必须修改root允许远程连接,或者添加一个允许远程连接的帐户1
2
3
4
5
6
7
8
9#进入mysql
[root@master ~]$ mysql -uroot -p123456
#修改root的远程访问权限
#root代表用户名 , %代表任何主机都可以访问 , 123456为root访问的密码
mysql> GRANT ALL PRIVILEGES ON root.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
#flush privileges刷新MySQL的系统权限,使其即时生效,否则就重启服务器
mysql> FLUSH PRIVILEGES;
#退出
mysql> exit;
安装hive
解压安装包
1 | tar -zxvf apache-hive-2.3.3-bin.tar.gz |
配置环境变量,这里不加赘述
配置Hive
1 | cd hive-2.3.3/conf/ |
hive的所有配置文件都不需要自己写,在安装包中已经包含了所有的配置文件,所以只需要改名就可以打开直接配置
修改hive-evn.sh
1 | export JAVA_HOME=/home/dc2-user/java/jdk1.8.0_191 ##Java路径 |
修改hive-site.xml
在这个配置文件中,发现会用很多很多的配置项,但是只需要修改几个属性的value就可以
vim的搜索功能看本文最上面的部分1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26vi hive-site.xml
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive-${user.name}</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/${user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/hive/resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name> hive.querylog.location</name>
<value>/tmp/${user.name}</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/tmp/${user.name}/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
配置Hive Metastore
Hive Metastore 是用来获取 Hive 表和分区的元数据,本例中使用 mariadb 来存储此类元数据。
将 mysql-connector-java-5.1.40-bin.jar 放入 $HIVE_HOME/lib 下并在 hive-site.xml 中配置 MySQL 数据库连接信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!-- 开启metastore远程连接 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
为Hive创建Hdfs目录
1 | start-all.sh #如果在安装配置hadoop是已经启动,则此命令可省略 |
启动Hive
1 | [root@master lib]# cd $HIVE_HOME/bin |
版本报错
将配置文件中hive.metastore.schema.verification的属性改为false
sqoop组件部署
修改配置文件
conf 下面的 sqoop-env.sh 文件
配置 haddop hive hbases环境变量
拷贝mysql-connector-java-*至 $SQOOP_HOME/lib
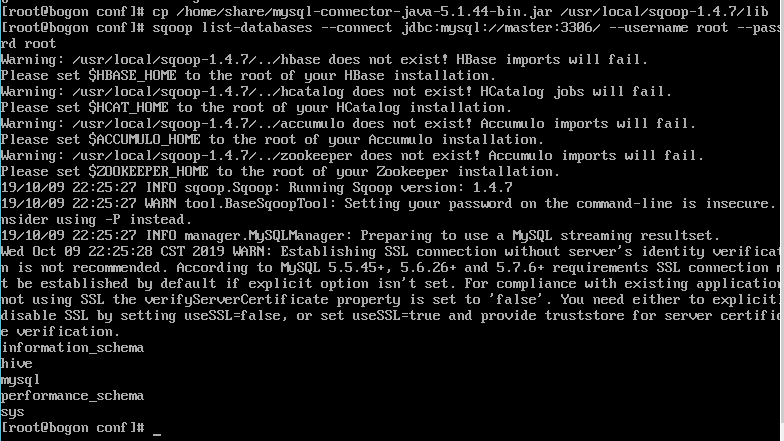
1 | cp mysql-connector-java-5.1.44-bin.jar $SQOOP_HOME/lib |
修改环境变量
测试sqoop,连接mysql数据库
1 | sqoop list-databases --connect jdbc:mysql://master:3306/ --username root --password root |
参考资料
感谢各位大佬的分享
https://blog.csdn.net/baidu_36414377/article/details/85554824
https://blog.csdn.net/l1028386804/article/details/88014099
https://blog.csdn.net/qq_32808045/article/details/77152496
https://www.cnblogs.com/liuhouhou/p/8975812.html
https://www.cnblogs.com/zlslch/p/9190906.html
https://blog.csdn.net/gywtzh0889/article/details/52818429
https://blog.csdn.net/qq_39142369/article/details/90442686
https://blog.csdn.net/weixin_41804049/article/details/81637750
https://blog.csdn.net/hhj724/article/details/79094138
https://www.cnblogs.com/wormgod/p/10761933.html
https://blog.csdn.net/cndmss/article/details/80149952
https://blog.csdn.net/adamlinsfz/article/details/84108536
https://blog.csdn.net/adamlinsfz/article/details/84333389
https://www.cnblogs.com/Jomini/p/10749657.html
https://blog.csdn.net/lxyuuuuu/article/details/83109287
https://blog.csdn.net/yumingzhu1/article/details/80678525
https://blog.csdn.net/dwld_3090271/article/details/50747639
https://blog.csdn.net/tao_wei162/article/details/84763035

